Interline Therapeutics is a pioneering drug discovery startup with a mission to revolutionize medicine at the molecular level. Utilizing their unique discovery platform, Interline focuses on deciphering the intricacies of protein communities to formulate groundbreaking medicines. Their goal extends beyond the traditional drug discovery methods by targeting genetically validated signaling pathways and recalibrating dysfunctional disease networks.
Interline Therapeutics is a drug discovery startup focused on systematically elucidating protein communities for identifying new medicines. Their discovery platform is used to identify new medicines targeting genetically validated signaling pathways and to ensure that their drug candidates comprehensively correct dysfunctional disease networks. Advances in multiple disciplines are aligning to expose previously hidden dimensions of protein communities in their native context. Interline is using this information to develop new medicines for genetically validated signaling pathways.
Interline faced a number of initial pain points as they began to build out their MVP and data lake which focused on High Performance Computing (HPC) involving genomics processing. The following are two of the biggest issues they faced.
Inconsistent Data
Interline Therapeutics' data was heterogeneous and arrived from multiple sources. As a result, the data input was in multiple formats. This created difficulties when attempting to connect and centralize all of the separate data sources including genomics and LIMS.
Proper Movement and Storage of Data
Interline was also unsure of the best way to move and store their data. They were considering options such as having multiple Amazon Simple Storage Service (S3) buckets for different types of data or having fewer S3 buckets for map reduce. Additionally, they were considering using a graph database such as Amazon Neptune, but were unsure if that was the best fit for their needs.
 Demonstrated Expertise in HPC
Cloud303 possesses specialized expertise in HPC, which is crucial for applications that require complex computational processes. This includes genomics sequencing, molecular modeling, and advanced simulations.
Demonstrated Expertise in HPC
Cloud303 possesses specialized expertise in HPC, which is crucial for applications that require complex computational processes. This includes genomics sequencing, molecular modeling, and advanced simulations. Cloud303's engagements follow a streamlined five-phase lifecycle: Requirements, Design, Implementation, Testing, and Maintenance. Initially, a comprehensive assessment is conducted through a Well-Architected Review to identify client needs. This is followed by a scoping call to fine-tune the architectural design, upon which a Statement of Work (SoW) is agreed and signed.
The implementation phase kicks in next, closely adhering to the approved designs. Rigorous testing ensures that all components meet the client's specifications and industry standards. Finally, clients have the option to either manage the deployed solutions themselves or to enroll in Cloud303's Managed Services for ongoing maintenance, an option many choose due to their high satisfaction with the services provided.

AWS Account Structure for Robust Governance
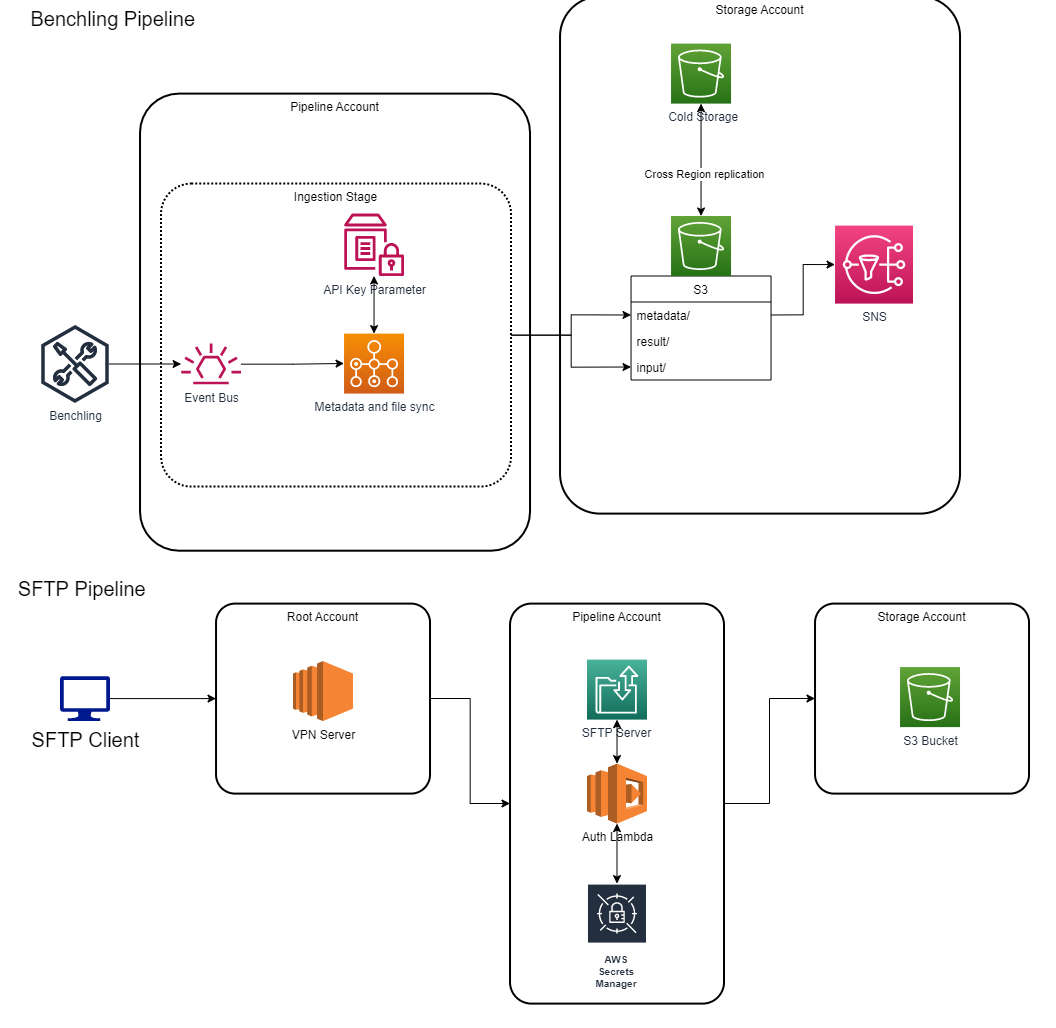
To help Interline overcome these challenges, Cloud303, an AWS Premier Consulting Partner, was brought in to assist with the deployment of their HPC pipeline on AWS. Cloud303 delivered three accounts to Interline: a Pipeline Account to process all the data required for their project, a Storage Account to store all the files and metadata needed for further studies, and an Audit Account to centralize logging for auditing purposes. Additionally, a Root Account was set up as the main AWS Organizations account for users to login into all other accounts. This account also created the entry and exit point for all internet traffic inbound and outbound.
Facilitating High-Performance Computing Workloads
To facilitate the compute workload, Cloud303 deployed AWS Batch and used AWS Lambda functions to invoke the pipelines and process data. All of their files were stored in an S3 Bucket with Cross Region Replication to ensure a disaster recovery plan was in place. Amazon Redshift was used to store all of the metadata necessary for Interline, and Amazon FSx for Luster was used as scratch storage for the pipelines, storing temporary files and enabling parallel computing if required in the future.
Integration of Proteomics Tools for Enhanced Data Analysis
To better support Interline's drug discovery process and handle the complexities of life sciences data, Cloud303 integrated proteomics tools such as Rosetta and Alphafold into the AWS-based HPC solution. This allowed Interline to systematically process and analyze large amounts of genomics and proteomics data, providing valuable insights into protein communities and their interactions.
Building the Benchling Pipeline for Streamlined Data Ingestion
For the benchling pipeline, Cloud303 set up an Event Bus to push events from Benchling and trigger AWS Batch for the Ingestion stage. This process would take the transaction id to query the Benchling APIs that retrieved the uploaded metadata for the new DNA sequence, the file, and selected data. This process then stored this data in an S3 Bucket. Additionally, any recent metadata events were configured to trigger the AWS Lambda function that launched the AWS Batch pipeline for the processing stage.
Ensuring Secure and Compliant Data Ingestion
For any other manual data ingestion, Cloud303 provided Interline with an SFTP server using AWS Transfer Family. All connections to the SFTP server were made through a VPN Server deployed by Cloud303. Users could be added or removed using CloudFormation Templates. All credentials were stored in Secrets Manager, encrypted with custom Key Management Service (KMS) keys provided by Cloud303. These keys were configured with a rotation policy to rotate every 60 days. All logs produced by the SFTP server were pushed into the Audit account on an application logging bucket for retention to satisfy HIPAA Compliance.
Solving the data pipeline challenges for Interline wasn't just about technology, but understanding their mission. The AWS-based solutions we deployed, including the HPC pipeline and multi-account structure, have set Interline up for scalable, future growth in their drug discovery efforts.

By working with Cloud303, Interline successfully built and deployed a life sciences-focused HPC pipeline on AWS. This allowed them to automate their bioinformatics pipeline, seamlessly process vast amounts of genomics and proteomics data, and develop new therapeutic candidates more efficiently.
After the solution was implemented, Interline saw a dramatic improvement in both their efficiency and capacity for data processing. Prior to the collaboration with Cloud303, Interline took an average of 24 hours to process a certain volume of data. With the newly established HPC pipeline on AWS, this processing time was reduced to just 6 hours - a remarkable 75% improvement in processing speed. This expansion in capacity, coupled with increased speed, means that Interline can now handle larger datasets more swiftly, a critical factor in speeding up their drug discovery process.
Furthermore, the implementation of Cloud303's solution led to significant cost savings and an increase in data accuracy. Operational costs were reduced by 30%, freeing up substantial resources that could be redirected towards their core research and development efforts. At the same time, the efficient use of AWS services and the establishment of a more organized data pipeline led to a reduction in data errors. The error rate dropped by 40%, resulting in cleaner, more reliable data for Interline's critical work in drug discovery.
With the implementation of this robust, scalable, and cost-effective solution, Interline was not only able to improve their operational efficiency but also ensure HIPPA compliance, maintaining the integrity and confidentiality of the data processed. This has enabled Interline to remain focused on their core mission of developing new medicines, secure in the knowledge that their data is handled in a compliant and efficient manner.
Additionally, the multi-account structure provided by Cloud303 ensured application scalability for any future additions required by Interline, allowing them to adapt to the evolving needs of life sciences research easily. With the peace of mind that their data was being handled and stored in a compliant and efficient manner on AWS, Interline could focus on their core mission of drug discovery and advancing precision medicine.
